Статья была написана в 2016 году для компании IQ Systems и стала довольно популярна как букварь по основам. К сожалению, этой компании давно уже нет, так пусть хотя бы материал кому-то приносит пользу.
Постоянно сталкиваемся с тем, что в области MDM (Master Data Management) катастрофически отсутствуют понятные вводные материалы, позволяющие быстро разобраться что это, зачем и почему это важно. Попробуем это в меру сил исправить и объяснить языком бизнеса.
В этой области пока серьезный дефицит определенности, и даже Википедия, как ни странно, не вполне уверена что есть что. Поэтому будем объяснять своими словами и «на пальцах», с примерами.
Что есть что
Итак, все данные, которыми оперируют современные информационные системы, можно разделить на нормативно-справочную информацию, мастер-данные и транзакционные данные.
Нормативно-справочная информация (НСИ) или справочники и классификаторы — позволяют нам структурировать окружающий нас мир с целью его анализа. Как правило, справочники и классификаторы строятся в виде списков и деревьев. Например, мы распределяем все товары по товарным группам для того, чтобы ими было легче управлять. В мировой практике эту часть классифицируют как Reference Data, с соответствующим классом приложений и процессов – Reference Data Management.
Мастер-данные как правило отражают объекты реального мира, и их основные свойства, например: клиентов, товары, людей, офисы, транспортные средства. Их ключевое отличие от НСИ в том, что НСИ – это атрибуты, свойства, списки, и прочие плоскости классификации, но объекты, описываемые НСИ как правило не существуют в реальной жизни. Так, модель автомобиля – это элемент НСИ, а вот конкретный автомобиль с его свойствами – элемент мастер-данных.
Транзакционные данные – отражают наши действия с объектами мира (читай – объектами мастер-данных), события и взаимодействия. Мы в момент T отгрузили клиенту А товар Б в количестве Х и по цене Y. А потом в момент T1 получили с клиента А платеж на сумму Z, вот эти запись и будут транзакционными данными.
Если посмотреть на эти три группы, то мы увидим некоторую иерархию, отраженную на рисунке. НСИ используется для структурирования мастер-данных и транзакционных данных. Мастер-данные определяют структуру транзакционных данных. И только транзакционные данные являются конечным результатом цепочки.
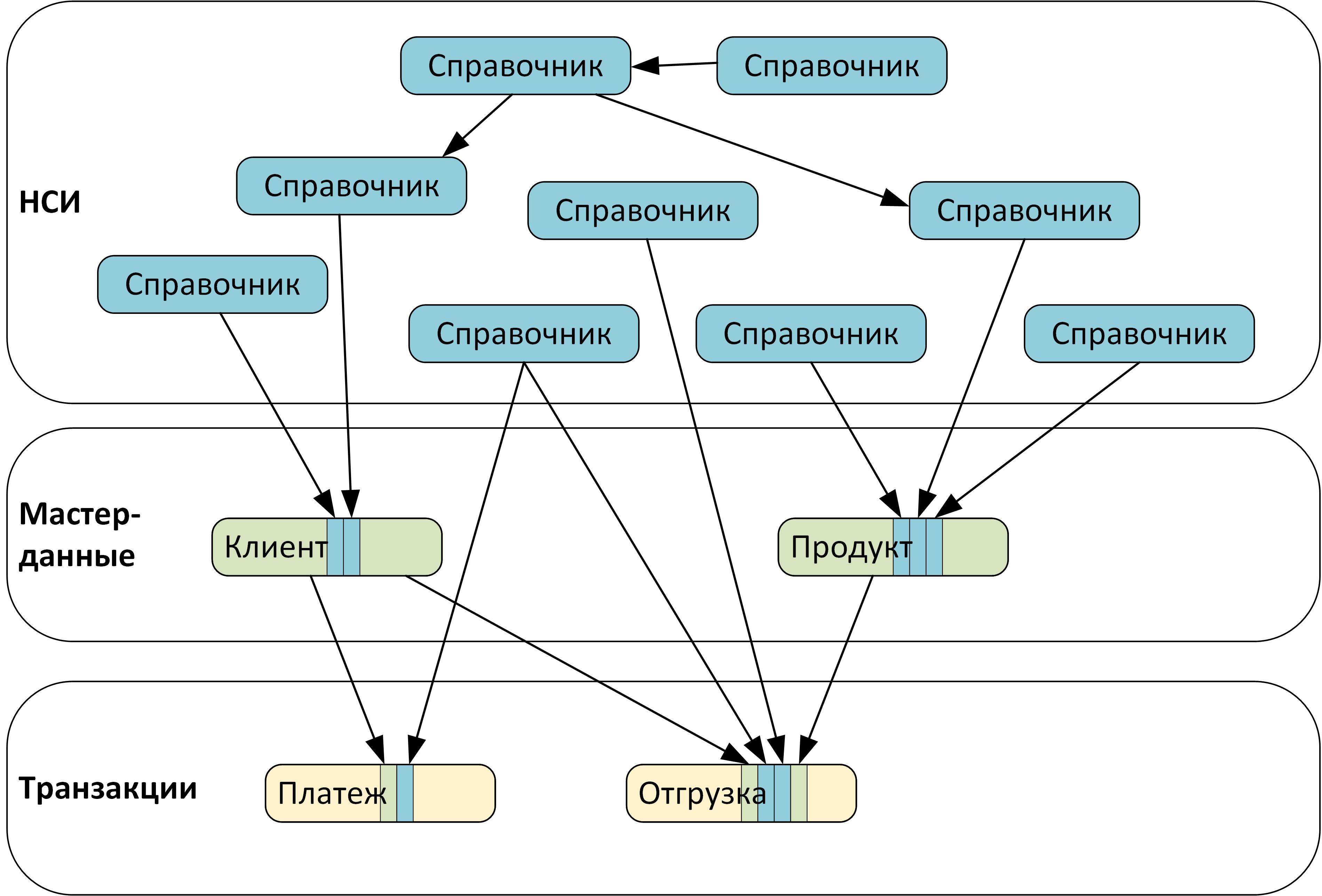
Таким образом, НСИ структурируют как мастер-данные, так и непосредственно транзакционные данные. Мастер-данные структурируют транзакционные данные. В результате наши аналитические возможности в отношении транзакционных данных прямо зависят от того, на сколько пригодный для наших целей «каркас» из НСИ и мастер-данных нам удалось построить.
Естественно, что каждый из видов данных обладает своими особенностями, которые мы обязаны рассмотреть подробно.
Особенности НСИ
Ключевой особенностью НСИ является их относительная неизменность, т.е. НСИ выстраиваются изначально исходя из бизнес-целей либо из устойчивой объективной реальности мира (например, справочник организационных форм или моделей авто). Изменения в НСИ обычно происходят в соответствии с определенной процедурой, ведение НСИ возлагается на конкретное подразделение. Всякое изменение должно обязательно пройти по определенному процессу согласования, гарантирующему целостность НСИ.
Источниками изменений в НСИ являются изменения в окружающей действительности, например, иногда появляются новые страны или валюты. Либо, если речь идет о справочниках, построенных вокруг бизнес-целей, — изменения, связанные с изменениями в бизнес-целях, учетной политике, распределении ответственности по товарным группам и т.д..
Фактически, НСИ формируют базовые плоскости аналитики, в силу чего состав и структура НСИ может быть достаточно сложной, в том числе одни справочники могут использоваться в других в качестве атрибутов, формируя сложные структуры, реализующие множество аналитических плоскостей. Например, для целей маркетинга, производства, управления запасами и финансового учета могут применяться совершенно разные группировки товарных позиций и разные наборы признаков.
При достаточной централизации управления НСИ система справочников обычно стабильна и не подвержена «зашумлению». Однако, в компаниях с недостаточно интегрированными приложениями мы наблюдаем одну и ту же беду: НСИ нередко строятся отдельно в рамках каждого приложения исходя из «локальных» бизнес-целей, обеспечиваемых этим приложением. В итоге порождаются «параллельные» наборы НСИ, не сведенные в единую систему, что сильно осложняет формирование аналитических массивов.
В идеале, управление НСИ должно быть централизовано. Таким образом в составе ИТ-решения появляется система RDM (Reference Data Management), обеспечивающая техническую и организационную основу для правления НСИ, по отношению к которой все остальные приложения являются клиентами односторонней синхронизации НСИ – из RDM в приложения.
Особенности мастер-данных
Мастер-данные более «подвижны»: новые клиенты, новые товары, новые люди – все это движение прямо происходит из жизни компании.
Важнейшей особенностью мастер-данных является то, что именно здесь компания накапливает знания о предмете своей работы. Вся информация, появляющаяся по ходу времени о конкретном клиенте должна хозяйственно складываться, структурироваться и обновляться, включая всю историю изменений. То же самое касается любых мастер-данных. Не менее важно то, что мастер-данные определяют так же отношения между разными сущностями. Что является филиалом чего, кто является поставщиком каких товарные групп, какие транспортные средства принадлежат каким филиалам и т.д.
Однако степень контроля за изменениями мастер-данных существенно ниже, ибо записи и их обновления порождаются в самых разных подразделениях, в разное время, вносится разными людьми, а зачастую еще и в разных системах, составляющих сложный ИТ-ландшафт современной компании. В результате нередко в каждой системе хранится лишь какая-то часть информации об одной и той же сущности, в каждой системе ей присваивается собственный идентификатор. В итоге формирование комплексной аналитической картины осложняется, а в особо запущенных случаях становится и вовсе невозможным.
В силу этого мастер-данные сильно подвержены «зашумлению» в результате ошибок и создания дублирующих записей. Как правило с этим борются организационными мерами, правилами типа «не заводить товарную позицию если она уже есть» или «перед тем как завести клиента – провести поиск по текущей клиентской базе». Но когда разбросанность по прикладным системам накладывается на многообразие написаний и описаний, а это все на пределы человеческого внимания и старательности – то никакие оргмеры не помогают.
Результатом «зашумления» является потеря качества мастер-данных, которая влечет за собой разрушение аналитики, ибо какая может быть аналитика если транзакции относительно одного реального клиента привязаны к трем разным клиентским записям, сделанным в разное время в разных системах разными людьми?
Крупные компании с большой историей и сложной ИТ-инфраструктурой запросто могут иметь в своих системах 15..20 млн клиентских записей о юрлицах в то время как всего юрлиц в России менее 5 млн. И это вполне жизненный случай. Про качественную клиентскую аналитику говорить здесь уже не приходится.
Другой пример. Очень подвержены «зашумлению» товарные каталоги. В силу отсутствия единого уникального идентификатора и разнообразия написаний нередко оператор не в состоянии соотнести новые товары с уже учтенными в системе. В результате позиция, пылящаяся на складе будет еще раз закуплена только потому, что складским остаткам соответствует одна карточка товара, а в проектных спецификациях – другая, хотя физически – это один и тот же товар.
Особо следует отметить, что большинство прикладных систем не содержит в себе сколько ни будь эффективных механизмов управления качеством этих данных, ограничиваясь тривиальным поиском по подстроке, уповая на добросовестность оператора и его знание прикладной области. Поэтому проблема качества мастер-данных обычно встает тогда, когда вносимые искажения и неадекватность аналитики достигают впечатляющих размеров и видны, что называется, невооруженным глазом.
Особенности транзакционных данных
Транзакционные данные являются самыми динамичными из всех перечисленных типов и по сути порождаются прозрачно для большинства операторов в ходе понятных действий типа «отгрузить товар», «загрузить выписку из банка». Как правило каждый элемент транзакционных данных содержит некоторое количество ссылок на записи мастер-данных разных видов плюс дату и ряд чисел, характеризующих транзакцию.
Например, минимальный элемент транзакционных данных, порождаемых отгрузкой будет состоять из ссылки на клиента, ссылки на товарную позицию, количества и цены. В реальности транзакционные данные имеют чуть более сложную структуру, так, например, есть накладная и соответствующий элемент данных с указанием контрагента и даты, а есть ее строки, каждая из которых содержит товарную позицию, количество и цену. И тем не менее для целей анализа число транзакционных записей будет равно числу строк в накладной, а сама запись, соответствующая накладной, — не перестает быть транзакционными данными.
Следует отметить, что всевозможные учетные регистры, содержащие, например, текущие остатки – по сути являются не транзакционными данными, а разновидностью аналитического обобщения. Просто это обобщение техническими средствами поддерживается постоянно актуальным и имеет целью оптимизацию производительности. Важно то, что оно в любой момент может быть пересчитано из транзакционных данных и в этом его принципиальное отличие – оно вторично.
Важно то, что транзакционные данные как правило затрагивают интересы внешних контрагентов, и в силу этого нет особых проблем с контролем их качества: например, если оператор задвоил отгрузку – то это скажется на балансе с контрагентом, приведет к разночтениям, сверке и ошибка будет скорректирована. Таким образом, взаимный контроль между взаимодействующими контрагентами вкупе с аналитическими инструментами и сложившейся бизнес-практикой обеспечивают сравнительно высокое качество транзакционных данных
Почему мастер-данные требуют особого подхода?
Определившись с понятиями и рассмотрев особенности типов данных, мы вплотную подошли к вопросу: почему же управление мастер-данными выделяется в отдельную функцию в современных ИТ-архитектурах? К тому есть несколько причин:
- Узкая функциональная направленность приложений зачастую приводит к тому, что каждое приложение оперирует своим набором атрибутов. Колл-центр не звонит на адрес офиса, доставка не привозит товары на емейл. Иначе говоря, полный набор информации, т.н. «мастер-запись» для каждого приложения избыточен. Вдобавок, в крупных организациях разные прикладные системы строятся под разные бизнес-цели и нередко оперируют даже разными НСИ. Разработчики и эксплуатанты функциональных приложений просто не испытывают нужды в «чужих» мастер-данных и НСИ в рамках своих целей, и вся эта проблематика в итоге обрушивается на системы высокоуровневой бизнес-аналитики, в которых мастер-данные и НСИ сводятся с тем или иным успехом. И об возникающих в этой точке проблемах граждане, вынужденные их решать могут говорить много, цветасто и вычурно, но как правило не очень литературно.
- Специфика алгоритмов работы с мастер-данными. Парадокс в том, что эффективное управление мастер-данными требует целого спектра подходов, которые в рамках прикладных систем обычно вниманием разработчиков не избалованы. Так, чтобы избегать дублирования записей необходимы очень гибкие и эффективные механизмы поиска и сравнения, сложные алгоритмы нормализации-валидации-сопоставления. При этом с точки зрения этих алгоритмов управление разными видам мастер-данных почти не отличается между собой. В общем-то все равно товарное ли это дерево, список транспортных средств, профили клиентов или личные карточки сотрудников. Подход не меняется, он прост: вычищать ошибки и опечатки, отлавливать и пресекать дубли, максимально дополнять и актуализировать, сохранять всю историю изменений, выделять «сомнительные» случаи для обработки аналитиками (дата-стюардами).
Таким образом и появляется в ИТ-ландшафте отдельный элемент – система управления мастер-данными (MDM, Master Data Management) как отдельная функция, ИТ-сервис, который «дирижирует» всей совокупностью мастер-данных компании, обеспечивая все функциональные приложения едиными, целостными, актуальными и полными мастер-данными. В большинстве случаев взаимодействие между прикладными системами и MDM происходит через шину данных, сообщения или SOAP/REST API.
Парадокс в том, что любая компания, пытающаяся построить высокоуровневую аналитику автоматически приходит к неявному формированию мастер-данных даже в том случае, если она использует ETL-процедуры для «перегрузки» данных из нескольких учетных систем в одну аналитическую, ибо качественная аналитика принципиально невозможна без качественных мастер-данных. Вопрос лишь в том, насколько развитые алгоритмы сопоставления используют ETL-процесс, какого качества мастер-данный получаются в целевой аналитической системе.
Таким образом, обусловленная спецификой мастер-данных невозможность действительно качественно решить задачу управления ими в рамках отдельной прикладной системы умноженная на большое количество прикладных систем порождает отдельный домен ИТ – управление мастер-данными.
Что такое MDM и какие они бывают?
Итак, управление мастер-данными или MDM выкристаллизовывается как отдельная область знаний и класс продуктов. Однако, в сложившейся в англоязычной терминологии это общий класс продуктов и решений, в который включается, в частности, ряд прикладных решений и связанных с ними бизнес-процессов:
- RDM, Reference Data Management, в общем и целом это – управление НСИ. Казалось бы, это не мастер-данные, это другой домен. Но отличие НСИ от мастер-данных заключается лишь в централизации, и тот же инструментарий, что мы используем для управления мастер-данными мы можем использовать и для НСИ с единственным отличием: все системы по отношению к RDM работают в режиме только чтения, а все изменения обязательно проходят через соответствующие бизнес-процессы.
- CDI, Customer Data Integration, интеграция клиентских данных. Под этим термином кроются системы, узко заточенные на работу с мастер-профилем клиента. Подразумевается, что эти системы агрегируют максимальный объем информации о клиенте и предоставляют всем другим системам сервисы поиска, создания и обновления клиентских записей, а также двунаправленной синхронизации.
- PIM, Product Information Management, система управления информацией о продуктах. Специализированный вид MDM, заточенный на информацию о продуктах, их свойствах и атрибутах. Например, такая система может быть «авторитетным источником» информации о продуктах для интернет-витрины, печатного каталога, ERP-системы и колл-центра одновременно, обеспечивая целостность представления и единство информации.
Нет сомнений, что при известной любви англоязычного мира к структурированию действительности, специализации и акронимам можно раскопать еще добрый десяток узких прикладных систем, которые по сути реализуют функционал управления мастер-данными в одной конкретной узкой области.
Формирующийся рынок MDM решений сегодня представлен большим количеством компаний, предлагающих решения очень разного качества. Все вендоры «первого эшелона» обозначили наличие в своем портфеле MDM решений или отдельно, или в составе своих систем. Однако, как и было сказано, большинство из них сосредоточено на другом функционале, поэтому качество реализации специфичного MDM функционала оставляет желать лучшего. В то же самое время множество небольших, но более сфокусированных на проблематике MDM компаний предлагает решения существенно более функциональные.
Нужен ли мне МДМ?
Итак, в каком случае Вам определенно стоит задуматься над внедрением MDM в свою ИТ-архитектуру? В первом приближении критерии следующие:
- У вас много мастер-данных. Десятки и сотни тысяч, а то и миллионы записей в той области, которую мы обозначили как мастер-данные. В первую очередь клиенты и товары. Как бы ни были хороши Ваши системы, такие объемы данных неизбежно «захламляются». И решить эту проблему штатными средствами Ваших систем скорее всего не получится. Наш опыт показывает, что даже при наличии заявленных «развитых механизмов дедубликации и обеспечения качества данных» количество дублей исчисляется десятками процентов от числа записей.
- У вас несколько функциональных систем с пересекающимся набором мастер-данных. Да, возможны варианты, когда архитектура изначально интегрирована должным образом, НСИ ведутся единообразно и данные разных систем правильно синхронизированы безо всякого посредника, а для каждого вида мастер-данных определена первичная система с которой синхронизируются все остальные. Однако это скорее исключение, чем правило. Чаще – все наоборот. И привести этот зоопарк к единообразию с помощью MDM системы будет на порядок проще, чем путем интеграции без выделенного MDM компонента.
- Синхронизация данных и сведение их в единую картину требует больших усилий, а результирующий аналитический массив вызывает сомнения. Многие компании используют стратегию, которую в двух словах можно описать так: «пусть оно в каждой системе живет как живет, а на уровне BI мы это как ни будь сведем» и используют сложные, громоздкие и не слишком эффективные ETL процедуры для того, чтобы формировать BI хранилище. К сожалению, это паллиативное решение, неповоротливое и весьма ресурсоемкое, заставляющее в каждодневном режиме «подкручивать» систему, хранить огромные массивы «нормализованных» данных, по сути выполняя огромную кучу работы по компенсации отсутствия MDM.
Последнее, что хотелось бы отметить в этом разделе – это то, что нет лучшего момента для внедрения МДМ, чем момент внедрения новых функциональных ИТ-систем или миграции с одних систем на другие. Ведь процесс внедрения подразумевает «очистку» накопленных данных и увязку систем между собой. Совмещая эти вещи мы одним выстрелом убиваем двух зайцев: повышаем качество данных в новой системе и одновременно сохраняем преемственность со старой, ведь MDM-система как раз и сшивает их между собой.
Куда катится MDM?
Чего следует ждать от этого направления? Каков вектор развития? Полагаем, что актуальными будут следующие тренды:
- Развитие «узкоспециализированных» MDM продуктов. Классы RDM, CDI и PIM выделены неспроста, это самые актуальные и доступные для понимания задачи MDM, решение которых несет максимальный эффект для бизнеса. Рекомендуем быть внимательными, ибо в текущем состоянии рынка «специализированный» скорее означает маркетинговое позиционирование, чем дополнительный функционал. Не факт, что «спец-MDM» от одного вендора будет решать задачу лучше, чем MDM общего назначения от другого.
- Улучшение MDM функционала в прикладных системах. Это происходит хотя бы через скупку вендорами «первого эшелона» меньших, но более продвинутых в этой области компаний. В первую очередь это коснется компаний, которые пытаются сформировать полностью моновендорный ИТ-ландшафт.
- Мини-решения и интеграция через стандартные API. Сейчас большинство MDM-решений – это тяжелые и дорогие корпоративные системы, эффективные только на масштабе. Они требуют сложной настройки, обученных специалистов, вдумчивой интеграции. И хотя эффект от их внедрения огромен, цена входного билета тоже весьма высока. Однако, как и многие технологии в ИТ они «пойдут вниз», со временем будут становиться все более доступны все меньшим компаниям.
- MDMasService. Очевидно, что нет никаких препятствий к тому, чтобы предоставлять MDM как услугу, наравне с другими приложениями. Открытые интерфейсы SaaS приложений способствуют их интеграции, так что вполне ожидаемо использование множества интегрированных друг с другом SaaS приложений, среди которых будет и SaaS MDM.
Заключение
Мы надеемся, что данный материал дал представление о том, что такое мастер-данные, что такое системы управления ими и зачем они нужны.
Определенно, для достаточно крупных организаций со сложным ИТ-ландшафтом MDM является совершенно необходимым элементом, позволяющим «склеить» воедино и сделать максимально полезными огромные, но сильно фрагментированные данные, упростить архитектуру, радикально снизить трудоемкость формирования бизнес-аналитики и одновременно существенно улучшить ее качество.